一、本文介绍
本文给大家带来的改进机制是低照度图像增强网络PE-YOLO中的PENet,PENet通过拉普拉斯金字塔将图像分解成多个分辨率的组件,增强图像细节和低频信息。它包括一个细节处理模块(DPM),用于通过上下文分支和边缘分支增强图像细节,以及一个低频增强滤波器(LEF),以捕获低频语义并减少高频噪声。同时该网络的发布版本并不完善,存在二次创新的机会,后期我会将其网络进行二次创新,增强低照度的检测性能。同时该网络发布版本存在Bug我也已经修复。欢迎大家订阅本专栏,本专栏每周更新3-5篇最新机制,更有包含我所有改进的文件和交流群提供给大家。
欢迎大家订阅我的专栏一起学习YOLO!

专栏回顾:YOLOv10改进系列专栏——本专栏持续复习各种顶会内容——科研必备
目录
一、本文介绍
二、PE-YOLO算法原理
2.1 PE-YOLO的基本原理
2.2 金字塔增强网络
2.3 细节处理模块
2.4 低频增强滤波器
三、PE-YOLO的核心代码
四、PE-YOLO的添加方式
4.1 修改一
4.2 修改二
4.3 修改三
关闭混合精度验证!
打印计算量的问题!
五、PE-YOLO的yaml文件和运行记录
5.1 PE-YOLO的yaml文件一
5.2 PE-YOLO的训练过程截图
五、本文总结
二、PE-YOLO算法原理

论文地址: 官方论文地址
代码地址: 官方代码地址

2.1 PE-YOLO的基本原理
PE-YOLO是一种改进的暗光条件下的物体检测模型。它结合了金字塔增强网络(PENet)和YOLOv3。PENet通过拉普拉斯金字塔将图像分解成多个分辨率的组件,增强图像细节和低频信息。它包括一个细节处理模块(DPM),用于通过上下文分支和边缘分支增强图像细节,以及一个低频增强滤波器(LEF),以捕获低频语义并减少高频噪声。PE-YOLO采用端到端的训练方法,简化训练过程。
PE-YOLO的基本原理可以分为几个关键点:
1. 金字塔增强网络(PENet): 使用拉普拉斯金字塔将图像分解为不同分辨率的组件,以提升细节和低频信息。
2. 细节处理模块(DPM): 包含上下文分支和边缘分支,专门用于增强图像的细节。
3. 低频增强滤波器(LEF): 用于捕获低频语义信息,同时减少高频噪声。
下面为大家展示了PE-YOLO系统的总览:
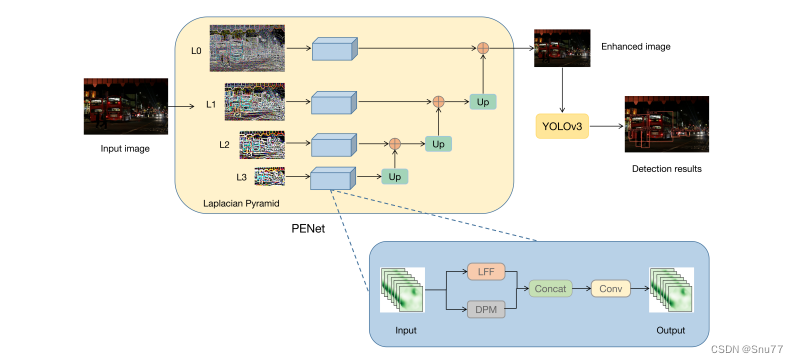
它说明了如何通过拉普拉斯金字塔将输入图像分解为不同层级(L0到L3),并通过PENet进行处理,最终提升图像质量以便进行物体检测。图中的细节处理模块(DPM)和低频增强滤波器(LEF)协同工作以增强图像。
2.2 金字塔增强网络
金字塔增强网络(Pyramid Enhancement Network)是PE-YOLO的关键组成部分,用于增强模型对不同尺度的目标的检测能力。
金字塔增强网络主要包括以下几个关键要点:
1. 多尺度特征金字塔:金字塔增强网络使用多个不同尺度的特征金字塔,这些金字塔包含了来自不同层级的特征图。这允许PE-YOLO同时检测不同大小的目标,从小尺寸物体到大尺寸物体都可以有效地检测。
2. 特征融合:金字塔增强网络通过特征融合的方式将来自不同尺度的特征图进行组合。这有助于提高模型对目标的定位和检测准确性,因为不同尺度的信息被有效地整合在一起。
3. 上采样和下采样:金字塔增强网络还包括上采样和下采样操作,以进一步调整特征金字塔的尺度。上采样用于增加分辨率,以更好地捕捉小目标的细节信息,而下采样则用于减小分辨率,以更好地捕捉大目标的全局信息。
4. 注意力机制:金字塔增强网络还引入了注意力机制,以使模型能够集中注意力在最重要的特征上,从而进一步提高检测性能。这有助于减少误检和漏检的情况。
总之,金字塔增强网络是PE-YOLO的关键创新之一,通过多尺度特征金字塔、特征融合、上采样、下采样和注意力机制等技术,提高了PE-YOLO模型在目标检测任务中的性能,使其能够更好地应对不同大小和尺度的目标。
2.3 细节处理模块
细节处理模块(Detail Processing Module,简称DPM)是PE-YOLO目标检测算法的一个关键组件,旨在增强模型对目标的细节信息的感知和处理能力。DPM的主要任务是通过上下文分支和边缘分支来对目标进行更详细的处理。
我为大家总结了PE-YOLO中细节处理模块(DPM)的主要特点和功能:
1. 上下文分支(Context Branch):上下文分支负责获取上下文信息,通过捕捉远程依赖关系来理解目标周围的环境。这有助于模型更好地理解目标与其周围环境的关系,从而提高目标检测的准确性。上下文信息的引入可以使模型更好地分辨目标和背景之间的区别。
2. 边缘分支(Edge Branch):边缘分支使用两个Sobel算子(Sobel operators)在不同方向上计算图像的梯度,从而获得目标的边缘信息。这有助于模型更好地识别目标的轮廓和边缘特征,并增强目标组件的纹理信息。边缘信息对于目标的细节识别和检测非常重要。
3. 组件增强:DPM的综合作用是增强目标的各个组件,包括上下文信息的增强和边缘信息的增强。这使得模型更能够准确地捕捉目标的细节特征,从而提高目标检测性能。
下图展示的是DPM的结构包括上下文分支(CB)和边缘分支(EB):
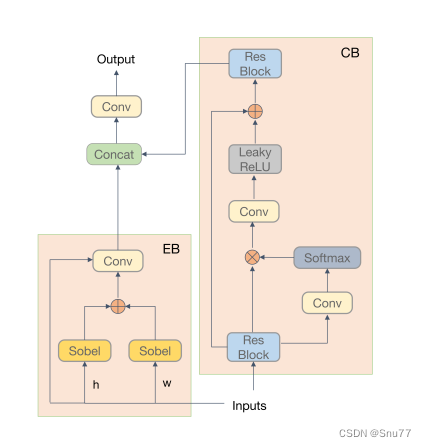
上下文分支通过捕捉远程依赖关系来获取上下文信息,并全局增强组件。
边缘分支使用两个不同方向的Sobel运算符来计算图像梯度,以获取边缘并增强组件的纹理。
2.4 低频增强滤波器
低频增强滤波器(Low-Frequency Enhancement Filter,简称LEF)用于捕捉和增强图像中的低频信息,这些低频信息通常包含了图像的大部分语义和关键信息,对于检测器的预测非常重要。
PE-YOLO中低频增强滤波器(LEF)的主要特点和功能总结如下:
1. 自适应平均池化:LEF使用不同尺寸的自适应平均池化操作来截取低频分量。这意味着LEF可以动态地适应不同尺度和语义的低频信息,以确保最大程度地捕捉图像中的关键细节。
2. 低频信息捕捉:LEF的主要任务是捕捉和增强图像中的低频信息,这些信息包含了图像的主要语义和关键细节。通过使用低通滤波器来过滤特征,LEF只允许低于截止频率的信息通过,从而增强了低频成分。
3. 多尺度处理:考虑到Inception的多尺度结构,LEF在不同的尺寸上应用自适应平均池化,以适应不同语义和尺度的低频信息。这有助于提高模型对图像细节的理解和捕捉。
4. 通道分离:LEF将特征f分为四个部分,即{f1, f2, f3, f4},通过通道分离的方式,每个部分都可以独立处理,以进一步增强低频信息。
下图展示了低频增强滤波器(LEF)的详细信息。LEF由不同大小的自适应平均池化组成,用于截取低频分量。
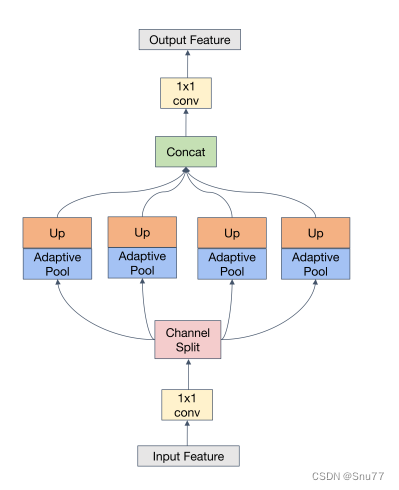
考虑到Inception的多尺度结构,我们使用了大小分别为1×1、2×2、3×3、6×6的自适应平均池化,并在每个尺度的末尾使用上采样来恢复特征的原始大小。不同核大小的平均池化形成了一个低通滤波器。我们通过通道分离将f分成四个部分,即{f1, f2, f3, f4}。每个部分都使用不同尺寸的池化进行处理,描述如下:
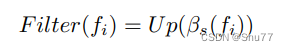
其中是分割在通道上的f的一部分,Up是双线性插值采样,
是不同尺寸s × s的自适应平均池化。最后,在张量拼接每个{
, i = 1, 2, 3, 4}之后,我们将它们还原为f ∈
。
三、PE-YOLO的核心代码
这个代码的使用方式比较特殊,大家需要注意看后面的使用教程!
import torch
import torch.nn as nn
import torch.nn.functional as F
class Lap_Pyramid_Conv(nn.Module):
def __init__(self, num_high=3, kernel_size=5, channels=3):
super().__init__()
self.num_high = num_high
self.kernel = self.gauss_kernel(kernel_size, channels)
def gauss_kernel(self, kernel_size, channels):
kernel = cv2.getGaussianKernel(kernel_size, 0).dot(
cv2.getGaussianKernel(kernel_size, 0).T)
kernel = torch.FloatTensor(kernel).unsqueeze(0).repeat(
channels, 1, 1, 1)
kernel = torch.nn.Parameter(data=kernel, requires_grad=False)
return kernel
def conv_gauss(self, x, kernel):
n_channels, _, kw, kh = kernel.shape
x = torch.nn.functional.pad(x, (kw // 2, kh // 2, kw // 2, kh // 2),
mode='reflect') # replicate # reflect
x = torch.nn.functional.conv2d(x, kernel, groups=n_channels)
return x
def downsample(self, x):
return x[:, :, ::2, ::2]
def pyramid_down(self, x):
return self.downsample(self.conv_gauss(x, self.kernel))
def upsample(self, x):
up = torch.zeros((x.size(0), x.size(1), x.size(2) * 2, x.size(3) * 2),
device=x.device)
up[:, :, ::2, ::2] = x * 4
return self.conv_gauss(up, self.kernel)
def pyramid_decom(self, img):
self.kernel = self.kernel.to(img.device)
current = img
pyr = []
for _ in range(self.num_high):
down = self.pyramid_down(current)
up = self.upsample(down)
diff = current - up
pyr.append(diff)
current = down
pyr.append(current)
return pyr
def pyramid_recons(self, pyr):
image = pyr[0]
for level in pyr[1:]:
up = self.upsample(image)
image = up + level
return image
class ResidualBlock(nn.Module):
def __init__(self, in_features, out_features):
super().__init__()
self.conv_x = nn.Conv2d(in_features, out_features, 3, padding=1)
self.block = nn.Sequential(
nn.Conv2d(in_features, in_features, 3, padding=1),
nn.LeakyReLU(True),
nn.Conv2d(in_features, in_features, 3, padding=1),
)
def forward(self, x):
return self.conv_x(x + self.block(x))
class PENet(nn.Module):
def __init__(self,
num_high=3,
gauss_kernel=5):
super().__init__()
self.num_high = num_high
self.lap_pyramid = Lap_Pyramid_Conv(num_high, gauss_kernel)
for i in range(0, self.num_high + 1):
self.__setattr__('AE_{}'.format(i), AE(3))
def forward(self, x):
pyrs = self.lap_pyramid.pyramid_decom(img=x)
trans_pyrs = []
for i in range(self.num_high + 1):
trans_pyr = self.__getattr__('AE_{}'.format(i))(
pyrs[-1 - i])
trans_pyrs.append(trans_pyr)
out = self.lap_pyramid.pyramid_recons(trans_pyrs)
return out
class DPM(nn.Module):
def __init__(self, inplanes, planes, act=nn.LeakyReLU(negative_slope=0.2, inplace=True), bias=False):
super(DPM, self).__init__()
self.conv_mask = nn.Conv2d(inplanes, 1, kernel_size=1, bias=bias)
self.softmax = nn.Softmax(dim=2)
self.sigmoid = nn.Sigmoid()
self.channel_add_conv = nn.Sequential(
nn.Conv2d(inplanes, planes, kernel_size=1, bias=bias),
act,
nn.Conv2d(planes, inplanes, kernel_size=1, bias=bias)
)
def spatial_pool(self, x):
batch, channel, height, width = x.size()
input_x = x
# [N, C, H * W]
input_x = input_x.view(batch, channel, height * width)
# [N, 1, C, H * W]
input_x = input_x.unsqueeze(1)
# [N, 1, H, W]
context_mask = self.conv_mask(x)
# [N, 1, H * W]
context_mask = context_mask.view(batch, 1, height * width)
# [N, 1, H * W]
context_mask = self.softmax(context_mask)
# [N, 1, H * W, 1]
context_mask = context_mask.unsqueeze(3)
# [N, 1, C, 1]
context = torch.matmul(input_x, context_mask)
# [N, C, 1, 1]
context = context.view(batch, channel, 1, 1)
return context
def forward(self, x):
# [N, C, 1, 1]
context = self.spatial_pool(x)
# [N, C, 1, 1]
channel_add_term = self.channel_add_conv(context)
x = x + channel_add_term
return x
import cv2
from torchvision import transforms
def sobel(img):
device = img.device
add_x_total = torch.zeros(img.shape)
for i in range(img.shape[0]):
x = img[i, :, :, :].squeeze(0).cpu().detach().numpy().transpose(1, 2, 0)
x = x * 255
x_x = cv2.Sobel(x, cv2.CV_64F, 1, 0)
x_y = cv2.Sobel(x, cv2.CV_64F, 0, 1)
add_x = cv2.addWeighted(x_x, 0.5, x_y, 0.5, 0)
add_x = transforms.ToTensor()(add_x).unsqueeze(0)
add_x_total[i, :, :, :] = add_x
add_x_total = add_x_total.to(device)
return add_x_total
class AE(nn.Module):
def __init__(self, n_feat, reduction=8, bias=False, act=nn.LeakyReLU(negative_slope=0.2, inplace=True), groups=1):
super(AE, self).__init__()
self.n_feat = n_feat
self.groups = groups
self.reduction = reduction
self.agg = nn.Conv2d(6,
3,
1,
stride=1,
padding=0,
bias=False)
self.conv_edge = nn.Conv2d(3, 3, kernel_size=1, bias=bias)
self.res1 = ResidualBlock(3, 32)
self.res2 = ResidualBlock(32, 3)
self.dpm = nn.Sequential(DPM(32, 32))
self.conv1 = nn.Conv2d(3, 32, kernel_size=1)
self.conv2 = nn.Conv2d(32, 3, kernel_size=1)
self.lpm = LowPassModule(32)
self.fusion = nn.Conv2d(6, 3, kernel_size=1)
def forward(self, x):
s_x = sobel(x)
s_x = self.conv_edge(s_x)
res = self.res1(x)
res = self.dpm(res)
res = self.res2(res)
out = torch.cat([res, s_x + x], dim=1)
out = self.agg(out)
low_fea = self.conv1(x)
low_fea = self.lpm(low_fea)
low_fea = self.conv2(low_fea)
out = torch.cat([out, low_fea], dim=1)
out = self.fusion(out)
return out
class LowPassModule(nn.Module):
def __init__(self, in_channel, sizes=(1, 2, 3, 6)):
super().__init__()
self.stages = []
self.stages = nn.ModuleList([self._make_stage(size) for size in sizes])
self.relu = nn.ReLU()
ch = in_channel // 4
self.channel_splits = [ch, ch, ch, ch]
def _make_stage(self, size):
prior = nn.AdaptiveAvgPool2d(output_size=(size, size))
return nn.Sequential(prior)
def forward(self, feats):
h, w = feats.size(2), feats.size(3)
feats = torch.split(feats, self.channel_splits, dim=1)
priors = [F.upsample(input=self.stages[i](feats[i]), size=(h, w), mode='bilinear') for i in range(4)]
bottle = torch.cat(priors, 1)
return self.relu(bottle)
if __name__ == "__main__":
# Generating Sample image
image_size = (1, 3, 224, 224)
image = torch.rand(*image_size)
# Model
mobilenet_v1 = PENet()
out = mobilenet_v1(image)
print(out.size())四、PE-YOLO的添加方式
这个添加方式和之前的变了一下,以后的添加方法都按照这个来了,是为了和群内的文件适配。
4.1 修改一
第一还是建立文件,我们找到如下ultralytics/nn/modules文件夹下建立一个目录名字呢就是'Addmodules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。

4.2 修改二
第二步我们在该目录下创建一个新的py文件名字为'__init__.py'(用群内的文件的话已经有了无需新建),然后在其内部导入我们的检测头如下图所示。

4.3 修改三
第三步我门中到如下文件'ultralytics/nn/tasks.py'进行导入和注册我们的模块(用群内的文件的话已经有了无需重新导入直接开始第四步即可)!
从今天开始以后的教程就都统一成这个样子了,因为我默认大家用了我群内的文件来进行修改!!
到此就完事了注册的工作,该模型无需添加任何参数是一种无参的机制,所以导入进来即可,该网络本身存在一个设备定义的错误,我解决以后需要关闭混合精度验证这是必须的否则会报错,其次该网络修改完打印不出来参数,都可以通过下面的步骤来解决。大家注意看!!
关闭混合精度验证!
找到'ultralytics/engine/validator.py'文件找到 'class BaseValidator:' 然后在其'__call__'中 self.args.half = self.device.type != 'cpu' # force FP16 val during training的一行代码下面加上self.args.half = False
打印计算量的问题!
计算的GFLOPs计算异常不打印,所以需要额外修改一处, 我们找到如下文件'ultralytics/utils/torch_utils.py'文件内有如下的代码按照如下的图片进行修改,有一个get_flops的函数我们直接用我给的代码全部替换!
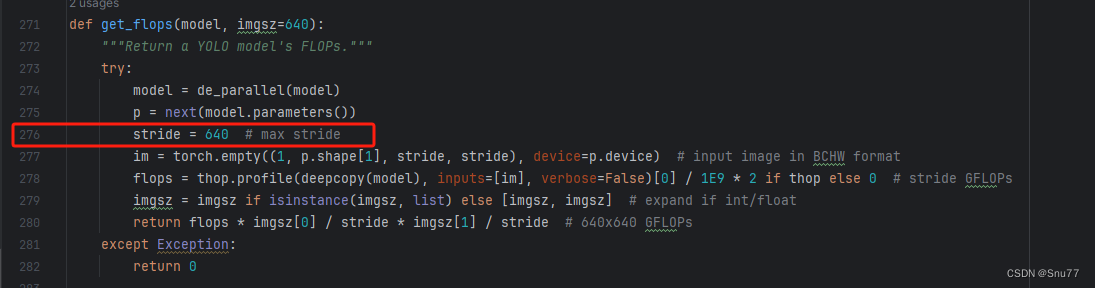
def get_flops(model, imgsz=640):
"""Return a YOLO model's FLOPs."""
if not thop:
return 0.0 # if not installed return 0.0 GFLOPs
try:
model = de_parallel(model)
p = next(model.parameters())
if not isinstance(imgsz, list):
imgsz = [imgsz, imgsz] # expand if int/float
try:
# Use stride size for input tensor
stride = 640
im = torch.empty((1, 3, stride, stride), device=p.device) # input image in BCHW format
flops = thop.profile(deepcopy(model), inputs=[im], verbose=False)[0] / 1e9 * 2 # stride GFLOPs
return flops * imgsz[0] / stride * imgsz[1] / stride # imgsz GFLOPs
except Exception:
# Use actual image size for input tensor (i.e. required for RTDETR models)
im = torch.empty((1, p.shape[1], *imgsz), device=p.device) # input image in BCHW format
return thop.profile(deepcopy(model), inputs=[im], verbose=False)[0] / 1e9 * 2 # imgsz GFLOPs
except Exception:
return 0.0
五、PE-YOLO的yaml文件和运行记录
5.1 PE-YOLO的yaml文件
训练信息:YOLOv10n-PEYOLO summary: 536 layers, 2807993 parameters, 2807902 gradients, 30.9 GFLOPs
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv10 object detection model. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov10n.yaml' will call yolov10.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, PENet, []] # 0-P1/2
- [-1, 1, Conv, [64, 3, 2]] # 1-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 2-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 4-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, SCDown, [512, 3, 2]] # 6-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, SCDown, [1024, 3, 2]] # 8-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 10
- [-1, 1, PSA, [1024]] # 11
# YOLOv10.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 7], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 14
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 5], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 20 (P4/16-medium)
- [-1, 1, SCDown, [512, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 3, C2fCIB, [1024, True, True]] # 23 (P5/32-large)
- [[17, 20, 23], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
5.2 PE-YOLO的训练过程截图

五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv10改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv10改进系列专栏——本专栏持续复习各种顶会内容——科研必备



![前沿重器[53] | 聊聊搜索系统6:精排](https://img-blog.csdnimg.cn/img_convert/d07675bbfde5a98075ade80fe90561dc.png)





![[氮化镓]Kevin J. Chen组新作—肖特基p-GaN HEMTs正栅ESD机理研究](https://i-blog.csdnimg.cn/direct/c8cd05eef36348da888c6f98b82c241e.png)